Utilizando arquivos de teste para análise do modelo de IA
O arquivo de teste é uma lista de interações críticas que se deseja que o modelo de NLP classifique. Modelo este criado usando a base de conhecimento (intenções e entidades).
O objetivo da criação deste arquivo é possibilitar a validação da assertividade do modelo, mais especificamente, garantir que o modelo identifique corretamente as intenções para as interações mais críticas do chatbot. Entende-se por perguntas críticas as interações relacionadas às skills (e conteúdos) que o chatbot não pode, em hipótese nenhuma, deixar de responder.
A recomendação é que sejam coletadas interações reais dos usuários que estejam dentro dos assuntos críticos mencionados acima.
Dica: Use os filtros da Tela de Aprimoramento para encontrar essas interações.
Esse arquivo é importante, pois assim é possível validar as modificações feitas na base, garantindo que tais alterações não gerem nenhum impacto negativo ao modelo, ou seja, tudo o que era reconhecido continua sendo reconhecido corretamente.
O arquivo deve estar no formato .csv, onde a primeira coluna contém as perguntas e a segunda o id da intenção que se espera que o modelo reconheça para aquela pergunta, utilize a ferramenta BLiP Build AI Model Analysis File para construir este arquivo facilmente.
Utilização
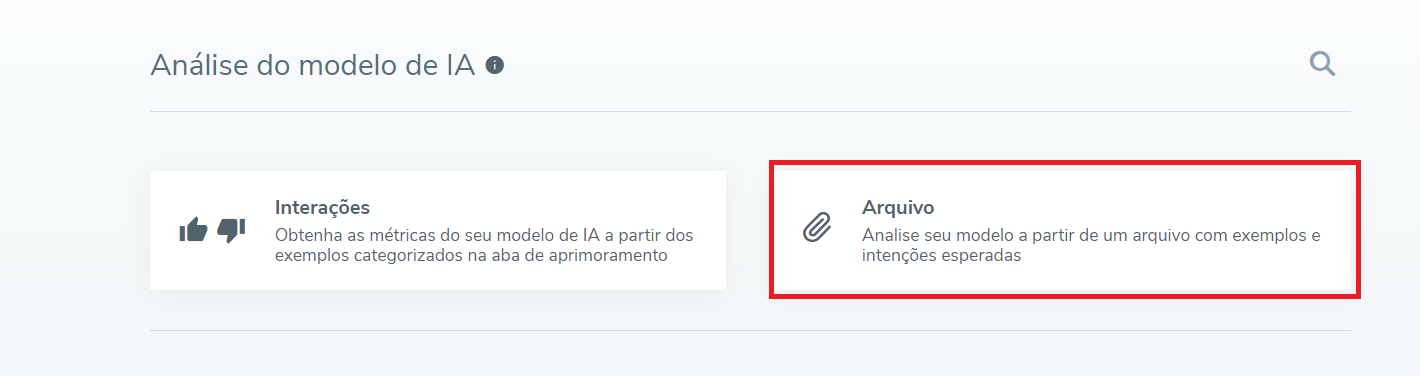
O uso do arquivo é feito na tela Análise do modelo de IA, onde pode-se criar o relatório com métricas de avaliação do modelo de IA. Deve-se escolher a opção de Arquivo e seguir as orientações.
Lembrando que para gerar o relatório é necessário que o BLiP envie as perguntas para o modelo, o que pode gerar custos dependendo do provedor utilizado.
Resultados
As métricas apresentadas pelo relatório, são:
Acurácia
Precisão
Recall
F1 Score
Confiabilidade média
Classificados corretamente
Classificados incorretamente
Top Falsos Positivos
Top Falsos Negativos
No caso do relatório criado com o arquivo de teste, as métricas geradas devem ter os seguintes valores da tabela abaixo:
| Acurácia | 1,00 |
|---|---|
| Precisão | 1,00 |
| Recall | 1,00 |
| F1 Score | 1,00 |
| Confiabilidade Média | Variável |
| Classificados Corretamente | 100% |
| Classificados Incorretamente | 0% |
| Top Falsos Positivos | Nenhum |
| Top Falsos Negativos | Nenhum |
A Confiabilidade média é variável, pois este valor é a média da confiabilidade dada pelo provedor ao analisar cada uma das perguntas do arquivo de teste.
Caso o valor de alguma das outras métricas seja diferente do que está na tabela, significa que o modelo não está respondendo corretamente todas as perguntas. Sendo assim, a sugestão é conferir quais são elas nas abas Top Falsos Positivos e Top Falsos Negativos, onde é possível identificar qual intenção era esperada e qual foi reconhecida.
Além disso, também é gerado a Matriz de Confusão onde é possível identificar pontos de confusão entre intenções.
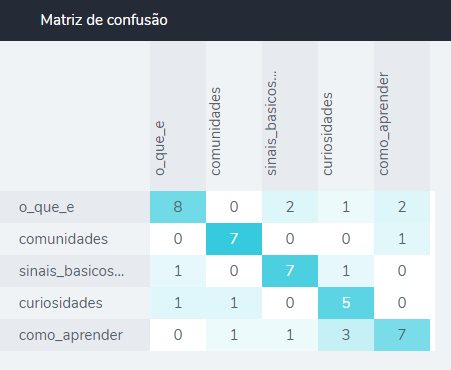
A coluna superior representa as intenções esperadas, enquanto a coluna da esquerda mostra as intenções reconhecidas.
Ex.: Era-se esperado que 10 perguntas fossem reconhecidas como Curiosidades, mas apenas 5 foram. Portanto, há confusão entre a intenção Curiosidades com a intenção O que é, Sinais básicos, e Como aprender, pois uma pergunta foi reconhecida como O que é, outra como Sinais básicos e outras 3 como Como aprender.
O cenário ideal da análise da matriz de confusão é que apenas a diagonal principal seja diferente de 0 (zero), e é esse cenário que se deve ter quando o arquivo de teste for usado para gerar o relatório.
Atualização do arquivo
O arquivo de teste deve conter as perguntas críticas relacionadas as skills (e conteúdos) que o chatbot não pode, em hipótese nenhuma, deixar de responder. Sendo assim, toda vez que o modelo for treinado e publicado deve-se adicionar interações que testem o que foi alterado na base (desde que seja algo crítico).
É importante salientar que não se deve adicionar exatamente o exemplo que foi adicionado à uma intenção mas, sim, uma interação que teste a capacidade do modelo de NLP de entender quando algo parecido for enviado ao chatbot.
Além disso, a recomendação é que a atualização (e operação) do arquivo seja feita pela mesma pessoa que fez as modificações na base de conhecimento (intenções e entidades) ou, no máximo, por alguém que tenha conhecimento das alterações que foram feitas.
Versionamento
Para controle de versão do arquivo recomenda-se que cada versão criada seja nomeada com o dia e hora da publicação do modelo a ser testado, para que se tenha uma relação entre a versão do arquivo e o respectivo modelo.
Se seguidas as recomendações feitas neste documento, a pessoa responsável pela evolução da base de conhecimento (e, consequentemente, do modelo de NLP) terá a capacidade de validar as modificações feitas na base, garantindo que, no geral, houve evolução e não retrocesso.
Além disso, cria-se um modo de garantir que o modelo responde corretamente aquilo que o cliente espera e, caso seja identificado algo que não é respondido, isso deve ser entendido como melhoria do modelo e não bug.